How to Scrape Data from a Website?
Request your data now
By clicking "Submit", you agree to our Privacy Policy
Web scraping allows and expedites the extracting of a large amount of data from websites without manually copy-pasting. In this article, you will learn about scraping data from a website. It covers information about determining a website source, checking alternatives sources with less anti-scraping protection, checking if the web scraping is legal, and finding data you need to extract from a page. You will also learn about creating templates that determine ways scraped data is delivered.
What is Web Scraping?
Various business needs, such as price comparison, contacts gathering, social media scraping, job listings, and research and development, require you to collect massive datasets. Most websites display data that users can only view using a web browser. However, they do not allow you to save a copy of the data for further use. Users interested in the information displayed on websites resort to copy-pasting the data from the site to a separate file. Deplorably, copy-pasting data from multiple webpages is slow and includes unnecessary data. Consider the time needed to copy-paste and repeat the same task for specific details in hundreds of web pages.
How can you collect such extensive information from one or multiple websites? Businesses and users apply web scraping, web data extraction, or web harvesting technique to extract massive data sets from websites. By and large, organizations deploy web scraping software that uses hypertext transfer protocol or web browsers to access the world wide web directly. An internet scraping application features web crawlers or bots that automate the process of copying specific unstructured information from the web into a spreadsheet or database for further analysis. Users can install Internet scraping software locally in their devices, or access it from the cloud.
Apart from online services and software, you can use APIs or write your code for website scraping. Occasionally, generic web scraping services are challenging to deploy and involve a steep learning curve. In such situations, businesses can build a custom data extraction tool for specific site scraping requirements. In most cases, developers use APIs that help them develop a scraping application quickly.
A web scraping service such as FindDataLab is secure, saves time, and offers a higher return on investment. Instead of spending increased IT operational costs and relying heavily on IT staff for development and support while building a custom Internet scraping tool or integrating APIs to your programs, you can quickly deploy this web scraping service. Finddatalab provides an all-inclusive scraping service with an easy point-and-click interface for users to scrape data from website. Besides, it allows you to select specific data based on your business requirements or use cases. The tool exports scraped data to a .CSV file format that users can further import into Excel or Google Sheets. The service handles all the technical tasks, including data cleansing and quality control.
How can you collect such extensive information from one or multiple websites? Businesses and users apply web scraping, web data extraction, or web harvesting technique to extract massive data sets from websites. By and large, organizations deploy web scraping software that uses hypertext transfer protocol or web browsers to access the world wide web directly. An internet scraping application features web crawlers or bots that automate the process of copying specific unstructured information from the web into a spreadsheet or database for further analysis. Users can install Internet scraping software locally in their devices, or access it from the cloud.
Apart from online services and software, you can use APIs or write your code for website scraping. Occasionally, generic web scraping services are challenging to deploy and involve a steep learning curve. In such situations, businesses can build a custom data extraction tool for specific site scraping requirements. In most cases, developers use APIs that help them develop a scraping application quickly.
A web scraping service such as FindDataLab is secure, saves time, and offers a higher return on investment. Instead of spending increased IT operational costs and relying heavily on IT staff for development and support while building a custom Internet scraping tool or integrating APIs to your programs, you can quickly deploy this web scraping service. Finddatalab provides an all-inclusive scraping service with an easy point-and-click interface for users to scrape data from website. Besides, it allows you to select specific data based on your business requirements or use cases. The tool exports scraped data to a .CSV file format that users can further import into Excel or Google Sheets. The service handles all the technical tasks, including data cleansing and quality control.
Use Cases of Website Scraping
Web scraping can help your business to remain competitive in the modern environment. The technique allows companies to collect and transfer crucial data from various sites to a usable format. Some of the site scraping use cases include:
Web scraping support data and data analysis and visualization for research projects.
Collecting vacancy posts and human resource management data from various job listing websites.
Price tracking and monitoring to allow your e-commerce business to track competitor prices and optimize your marketing intelligence.
Website scraping to extract essential business data, such as product catalogues, company list, yellow pages, statistical data, price tags, and text content.
Web scraping and analysis for marketing activities such as search engine optimization, discovering marketing data and collecting details about potential customers from a catalogue or open list.
Social media platform scraping to assess how your company and competitors' brands are performing online. Finddatalab.com enables you to collect data such as followers, engagement rates, likes-comment ratio, reviews, and so on from popular social media platforms like Twitter, Instagram, TikTok, YouTube, and Review Finder.
Determining a Website as a Source,
Checking for Alternatives
Virtually, everything available on the web can be a source for your data. Business requirements help determine a target website for scraping. After identifying a source, you can run a web scraping code that sends a request to the target site's URL. The server responds to the request by sending back data that you can read in the XML or HTML page. An Internet scraping service parses the page to find and extract the specific data.
Before starting data extraction, it is essential to check if a target website has anti-scraping protection, such as captcha or websites that do not restrict multiple requests from one IP address, since some site owners can make it difficult for bots to scrape data. Target sites can feature numerous scraper traps, web scraping captchas, and multiple defense layers to prevent bots and web crawlers from collecting data. A full-fledged scraper can, however, still bypass technical shields used to make a website scraping proof. Despite that, if a site owner implements scraping-proof measures, then it is considered illegal to scrape it.
Before starting data extraction, it is essential to check if a target website has anti-scraping protection, such as captcha or websites that do not restrict multiple requests from one IP address, since some site owners can make it difficult for bots to scrape data. Target sites can feature numerous scraper traps, web scraping captchas, and multiple defense layers to prevent bots and web crawlers from collecting data. A full-fledged scraper can, however, still bypass technical shields used to make a website scraping proof. Despite that, if a site owner implements scraping-proof measures, then it is considered illegal to scrape it.
Is Your Website Scraping Legal?
Web scraping is legal if you use the extracted data for lawful purposes.
You can assess a website's "robots.txt" file by appending "/robots.txt" to determine if it allows web scraping. Users should vitally respect the rules of the target sites by reading over their Terms of Service before scraping. In other contexts, if you're unsure about the owner's position on scraping activities, consider contacting the webmaster to grant permission to crawl their site. On the other hand, some websites restrict users and businesses from data extraction in specific cases. For instance, it is illegal to scrape the Internet for nonpublic and copyright-protected information.
The U.S. Computer Fraud and Abuse Act (CFAA) that prohibits intentionally accessing a computer without authorization or over authorization has become a tool ripe for use against a wide range of computer activities, including Internet scraping. Considering that the site scraping technique only accesses publicly available data, you would think that the CFAA does not apply in this case. However, some scrapers violate the law by stealing and manipulating personal data like social media images. GDPR, in the same vein, impacts web scraping. Unless a scraper has a subject's explicit consent, it is illegal to scrape an EU resident's publicly available personal information under the regulation. Personal information includes identifiable data that can directly or indirectly identify a specific individual. Examples of personal details include name, physical address, phone number, email scraping, credit card details, bank information, IP address, date of birth, employment information, social security number, video and audio recording, photos, and medical information.
The second revision to the draft California Privacy Act (CCPA) regulation, however, provides that a business that does not collect personal information directly from a consumer does not need to notify them at collection if it does not sell the subject's data. In that event, the CCPA regulation does not require data scraper experts who extract information for their use to provide a notice at collection.
You can assess a website's "robots.txt" file by appending "/robots.txt" to determine if it allows web scraping. Users should vitally respect the rules of the target sites by reading over their Terms of Service before scraping. In other contexts, if you're unsure about the owner's position on scraping activities, consider contacting the webmaster to grant permission to crawl their site. On the other hand, some websites restrict users and businesses from data extraction in specific cases. For instance, it is illegal to scrape the Internet for nonpublic and copyright-protected information.
The U.S. Computer Fraud and Abuse Act (CFAA) that prohibits intentionally accessing a computer without authorization or over authorization has become a tool ripe for use against a wide range of computer activities, including Internet scraping. Considering that the site scraping technique only accesses publicly available data, you would think that the CFAA does not apply in this case. However, some scrapers violate the law by stealing and manipulating personal data like social media images. GDPR, in the same vein, impacts web scraping. Unless a scraper has a subject's explicit consent, it is illegal to scrape an EU resident's publicly available personal information under the regulation. Personal information includes identifiable data that can directly or indirectly identify a specific individual. Examples of personal details include name, physical address, phone number, email scraping, credit card details, bank information, IP address, date of birth, employment information, social security number, video and audio recording, photos, and medical information.
The second revision to the draft California Privacy Act (CCPA) regulation, however, provides that a business that does not collect personal information directly from a consumer does not need to notify them at collection if it does not sell the subject's data. In that event, the CCPA regulation does not require data scraper experts who extract information for their use to provide a notice at collection.
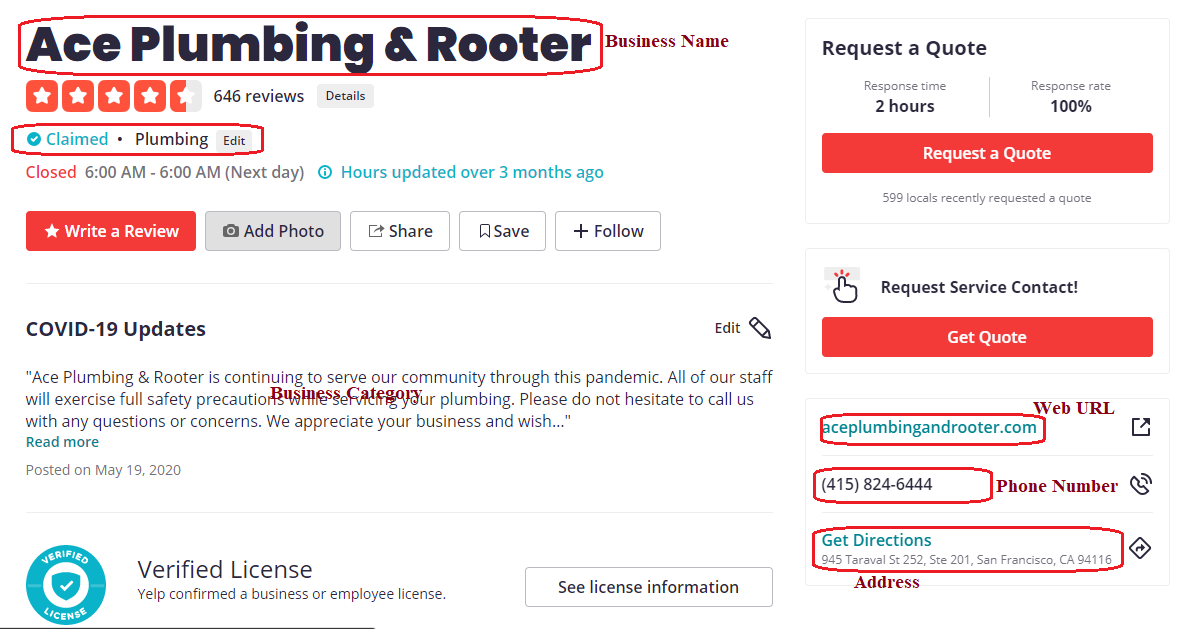
Finding the Data from Target Page(s)
With modern web scraping services, you get access to an interface that allows you to load websites and select the data that you need to extract. The software then identifies the patterns of data occurring in the target web page, scrapes it, and saves the structured information in various formats like Excel, XML, CXV, JSON, or TSV file.
Besides, you can scrape data from website or a page by automatically submitting a list of input keywords to search forms. Scraping services allow users to forward one or multiple input keywords to input text fields to perform a search.
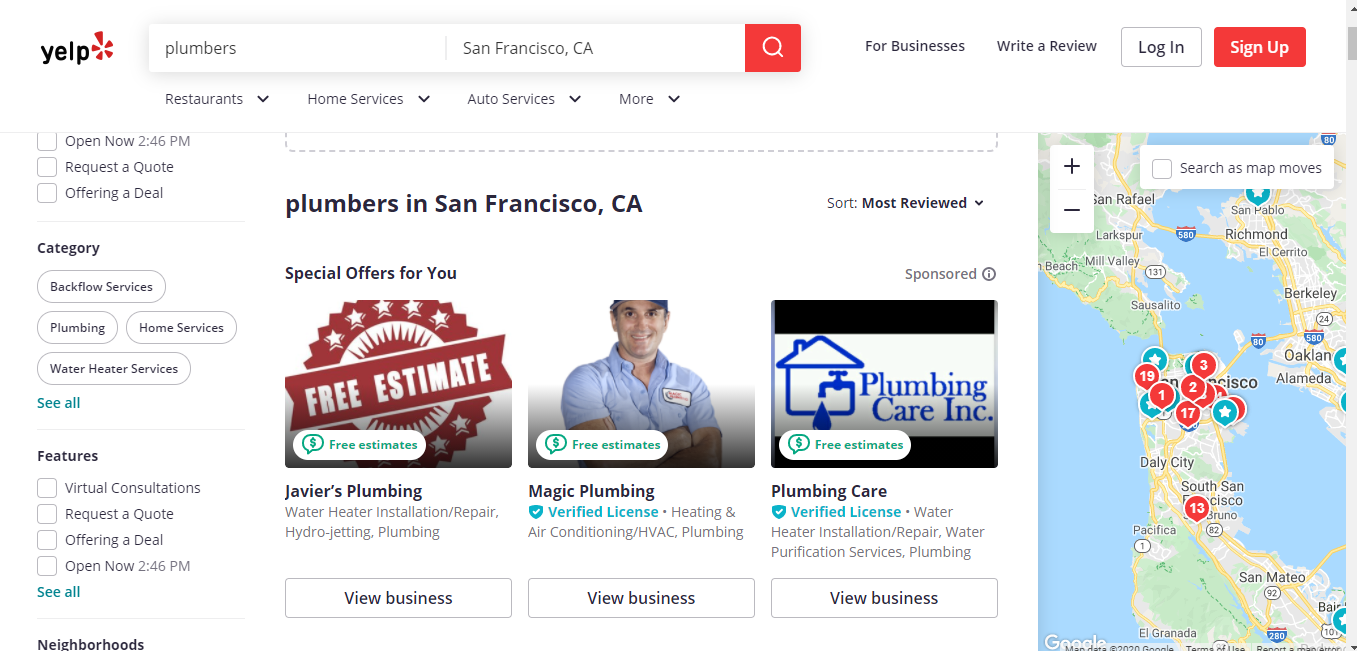
In our case, we will extract information about plumbers in San Francisco by following these simple steps:
This article demonstrates Internet scraping by extracting data from Yelp
Besides, you can scrape data from website or a page by automatically submitting a list of input keywords to search forms. Scraping services allow users to forward one or multiple input keywords to input text fields to perform a search.
In our case, we will extract information about plumbers in San Francisco by following these simple steps:
This article demonstrates Internet scraping by extracting data from Yelp

Query the target information by searching directly on Yelp
How to make a brief for web scraping service?
There are some things you should do together with sale intelligence and customer support specialist of a web scraping service:
- Make a simple template in an excel file for yourself or web scraping services in Excel to determine how do you want this data to be delivered.
- Mention your special needs and requests such as
- The website you want to scrape
- How often you need to scrape it
- If you need data from multiple sources, please describe how do you want it merged and compiled
- If you need to enrich the data, describe what additional information you may need in the final dataset
Ready to try?
Please share the details of your data needs, and our team will respond immediately
Data scraping project description
By clicking Submit, you agree to our Privacy Policy